

CxOs are in a race to identify Generative AI use cases for their Enterprises. While PoCs are happening, there are not many use cases that have gone into production. Apart from cost, the other key worry for leaders is the inaccuracy of the outputs of the Large Language Models (LLMs) for their specific use cases. While many methods can improve model accuracy, you should consider Retrieval-Augmented Generation (RAG) as a key piece in the puzzle.
Depending on the use case, implementation of RAG can make a world of difference in the accuracy and reliability of the language model. Let us delve deep into RAG and understand what it is and how we can implement it for our use cases. Before getting into the details of RAG, first let us see what the problem is which many of us are facing in our GenAI implementations.
Why we need RAG
As we know, LLMs have been pre-trained on a large corpus of data. While for retrieving historical information this data may be enough, it doesn’t help where up-to-date data is needed for reasoning. Moreover, researchers have pre-trained LLMs using only publicly available data. It was not trained with your organization specific data that is private to your enterprise.
Note that Function Calling is another technique that can be used for grounding the model with the required context. However, Function Calling can only be used in certain scenarios (e.g. where APIs are available) which makes RAG more applicable for most scenarios.
Now that we have understood the problem statement, let us look at what is RAG, what are the other problems it could solve, and how to implement it to make your Enterprise GenAI ready.
What is RAG
The term RAG seems to have been coined by Patrick Lewis and his team in 2020 for their conference paper titled “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”. They proposed RAG to improve the efficiency of Large pre-trained language models when deploying them on knowledge-intensive tasks.
To put it in simple terms and in the context of an enterprise, Retrieval-Augmented Generation (RAG) is a technique that can be used to feed enterprise-specific knowledge to a Large Language Model (LLM) so that it has the relevant context based on which the model can provide better quality responses to a user’s query. When used in appropriate use cases, RAG techniques can greatly reduce model ‘hallucinations’ (A hallucination is when an AI model produces incorrect, misleading or nonsensical response to user’s query) and improve the accuracy and reliability of LLM responses.
How a typical RAG implementation looks like
Here are the steps to implement a RAG system:
- Chunking
- Enriching
- Embedding
- Storing
- Query Pre-processing
- Comparing
- Retrieving
- Augmenting
- Generating
Out of these, the first 4 are about pre-processing the data and making it ready for consumption by the LLM. This happens during design time. The system performs the last five steps during runtime once a user submits a query that the LLM needs to answer. Let us look at each of these steps in some more detail.
RAG steps during design-time (Pre-processing)
Here are the steps to take to prepare the enterprise data for RAG:
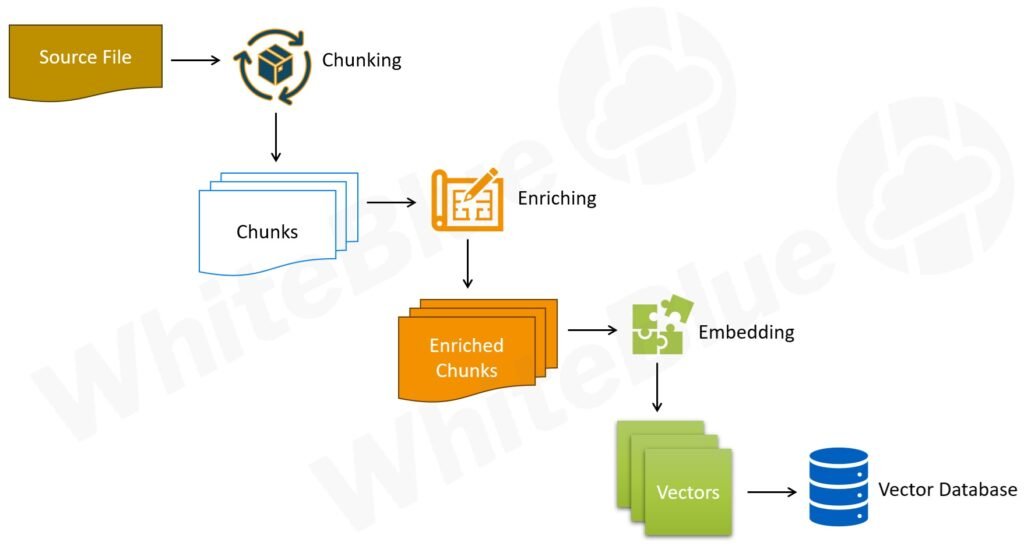
Chunking
The idea of Chunking is to feed ‘as less relevant data as possible’ to the LLM so that it can generate high quality output. The more irrelevant data the LLM is considering as its context, the higher the chances for hallucinations. So the ‘relevance’ of input has a big role to play in ensuring the quality of output. This makes chunking a very import step in the RAG process (also called a ‘RAG pipeline’ since the output of a step flows as an input to the next step).
The input for Chunking is the source document(s). These source documents are nothing but the enterprise-specific knowledge you have. These could be your policies, procedures, processes, SOPs, FAQs, or any other ‘knowledge’ you have in your enterprise repository.
Chunking basically means breaking your data (document) into multiple smaller fragments (chunks). Deciding how to chunk data to keep related information together is a strategy by itself that requires careful thought and a deep understanding of the structure of your data (document). There are different chunking methods available (Fixed size, Recursive, Semantic etc.); we will not go into the details of these different strategies in this article.
As mentioned above, the output of Chunking is chunks. Each chunk is expected to have only related information within that chunk.
Enriching
This is an optional step and is required if you are still having quality issues with your LLM responses even after trying out various chunking methods. In such scenarios, enriching your chunks can be an effective way to improve accuracy of the model responses.
Enriching mainly involves cleansing your chunks as well as augmenting them with relevant metadata. Cleansing allows you to achieve better matches for your queries by standardizing your data (document) and by removing insignificant elements in your data (document). Techniques like lowercasing, fixing spelling issues, standardizing the way certain business-specific terms are used in the document etc. helps in cleansing the data and making it more ‘semantic-search’ friendly (which we will talk about in sections below).
Adding metadata like Title, Summary, Keywords etc. additionally helps in getting a more relevant search result. If manually adding these metadata is very time-consuming, you can use an LLM to generate metadata for your chunks and automate the process.
Embedding
The process of embedding results in a mathematical representation of the data being embedded. The name for this mathematical representation is ‘Vector’. Two chunks which are ‘semantically’ similar results in Vectors that are similar.
To make this happen we will have to first choose an embedding model from the many different embedding models available. The embedding model you choose can have a significant impact on the relevancy of the vectors being returned as part of the search.
Every embedding model has a vocabulary based on which it is functioning. The more that vocabulary overlaps with the language you have in your data (document), the better that embedding model will be for your use case. This means that there could be a chance that you may have to fine-tune an embedding model with your domain-specific vocabulary before you use that model for doing your embedding.
In a RAG solution, the query (which user asks) is first embedded (resulting in a Vector) and then searched against a database (of Vectors) for retrieving ‘similar’ Vectors. This means that when a similarity search is performed, the vectors (and hence chunks) which are more relevant to the query would be returned. We will talk about this database in the following section.
Storing
Once the Vectors are generated, the next step is to store these Vectors along with the corresponding (non-embedded) chunks. There are special-purpose Vector databases which are optimized for Vector storage, search and retrieval. As mentioned above, Vectors are mathematical representations of the data and a Vector database helps in performing a similarity search on these Vectors resulting in retrieval of relevant (similar) chunks. These databases often support storage of non-vector datatypes also (strings, boolean values, integers etc.). This is how we are able to store the Vectors along with their corresponding non-embedded chunks (and metadata, if available).
A vector database uses a combination of different algorithms that results in a similarity search. We achieve this similarity search using a ‘Similarity Measure’. Similarity measures are mathematical methods for determining how similar two Vectors are in a vector space. Common similarity measures used by vector databases includes Euclidean distance, Dot product, Cosine similarity etc.
So far we have seen the pre-processing steps that are required for a RAG implementation. Following the above-mentioned steps ensures that your data is ready for being retrieved based on a semantic and similarity search.
Now we will look at how this search is actually getting performed when a user is asking a query to a Large Language Model that is prepared for RAG.
RAG steps during run-time (Query, Search and Retrieval)
Here are the steps that occur when the LLM processes a query:
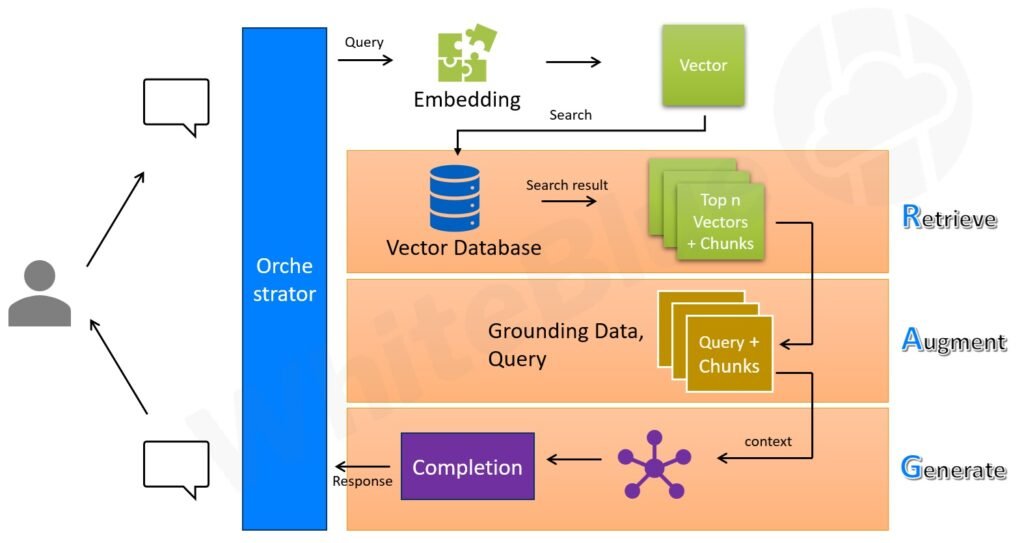
Query Pre-processing
When the user asks a query, first the query gets processed. Depending on your scenario and users, you may have to first break the query into subqueries and then pre-process each of these subqueries separately (An LLM can be used to decide on whether the query requires breaking into multiple subqueries, and to arrive at those subqueries). The exact methods to be followed for query (or subquery) pre-processing depends on the Enriching and Embedding steps followed during pre-processing the data.
During Enriching, if the data was cleansed, the exact same cleansing steps needs to be followed for the query also (e.g. lowercasing, fixing spelling issues etc.). Once the query is enriched, it needs to be embedded using the same Embedding model that was used for pre-processing the data. The output of this embedding step is that we will have a Vector that is a mathematical representation of the query.
Comparing
Now we have a Vector that represents the query asked by the User (or multiple Vectors in case the query had subqueries). Based on this Vector, a similarity search is performed against the vector database. Based on how we configure the vector database, the top ‘n’ Vectors that are ‘similar’ to the Vector being searched is returned along with their corresponding chunks and metadata (if any).
Optionally, it is also possible to have a secondary search (e.g. Full text search) based on keywords extracted from the plain-text query. In such cases, the keywords are searched against the metadata stored in the same vector database, which again results in one or more Vectors getting returned along with their corresponding chunks and metadata (if any).
If secondary searches are performed, there will have to be a custom logic written to re-rank the results based on the results returned by the primary vector search and the secondary keyword searches. There are vector databases available that supports ‘Hybrid queries’ in which case the database itself can do the primary and secondary search, and re-rank the results for you (eliminating the requirement for having a custom logic).
However, even if your vector database is supporting Hybrid queries, there could be scenarios when you may want to re-rank based on a custom logic. Another scenario for custom logic is when the original query had to be broken up into subqueries (each resulting in a Vector) and multiple searches had to be performed for each of those Vectors.
Retrieving
In this step, the data (document) available in the chunks that got returned as part of the output of step above is retrieved.
Augmenting
In this step, the data that is retrieved from the previous step is assembled as the ‘Grounding data’ for the LLM. The system sends this grounding data along with the query to the LLM. Thus, this step is about augmenting the query and providing relevant additional context to the LLM as grounding data. This augmentation is what helps LLMs to have the specific context which it can use to generate better quality outputs (completions).
Generating
In this step, LLM uses the grounding data and the query to generate the required output. Since the model now has the ‘relevant’ context, it has a more comprehensive understanding of the topic on which the query was raised by the user. This in turn results in the model generating better quality responses.
This makes RAG a powerful technique to make the overall solution more reliable and its response more accurate.
Summary
Retrieval-Augmented Generation has a big role in enhancing the accuracy and reliability of the Large Language Model (LLM) which you are using for your Generative AI use cases. RAG has the potential to improve the adoptability of your solution and can accelerate the overall adoption of GenAI in your Enterprise. Understanding what it takes to implement a RAG solution is necessary as you prepare your enterprise to become GenAI ready.
The future of RAG is incredibly promising as it represents a significant leap forward in the field of AI. By combining the strengths of retrieval-based and generation-based techniques, RAG systems can deliver more accurate, contextually relevant, and factually grounded responses. As AI continues to evolve, RAG will likely become integral in various applications, from enhancing virtual assistants and customer support systems to improving enterprise search systems and business intelligence dashboards.